



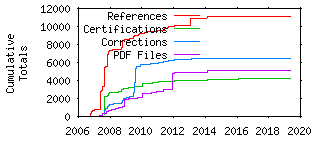
This database is a work-in-progress, and will change through time. Please contact us if you find any errors or discrepancies (you can do that from the “information” page of any reference).
What is the source of the PDFs?
We are grateful to the research community for supplying us with reference metadata and PDF files. Substantial contributions can be viewed on our database contribution summary page.
These PDF files come primarily from these sources:
- Original PDFs of newer material (not scanned)
- Scans from Google Book Search
- Scans from the Biodiversity Heritage Library
- Scans of printed material
For original PDFs, we usually place the PDF into the repository just as it is received. In a few cases, we have done some processing of the file to fix PDF problems or ease use of the material.
For scans from Google Book Search, the first page of the PDF will show the Google Book Search information. We have processed these files to remove blank pages and add optical character recognition (OCR) text underneath the images (to facilitate searching). In some cases we have extracted the relevant article(s) from whole-volume scans.
The Biodiversity Heritage Library (BHL) is an excellent repository of (mostly) pre-1923 systematic literature. In some cases we have extracted the relevant article from whole-volume scans at BHL.
Most of the files come from our scans of printed material. The process described below is the ideal case. Not all documents were treated that way, so some may have lower resolution than others.
How do we scan and process documents into PDFs?
Our procedures for scanning and processing documents aim to achieve a balance between scan resolution and file size.
We have extensively documented our procedures for scanning and processing PDF files. If you are considering scanning papers to contribute to our collection, we urge you to look at that documentation first. Please feel free to ask us any questions.

